The post What are the profits of building cloud services with SAP Cloud Application Programming Model (SAP CAP) appeared first on INT4.
]]>
Introduction
The world is going digital. It’s no secret anymore that more and more businesses are choosing to have their software delivered as a service and hosted in huge, secure data centers. In this software delivery changing process, the importance of simplicity can’t be understated. The number of applications, services or systems is constantly growing creating a much more complex world.
In order to meet a wide set of business criteria, an application or service is usually build at different platforms (such as SAP NetWeaver, SAP Web IDE) and using different languages (ABAP, CDS, UI5/Fiori).
This may raise a challenge: how to simplify a process of building enterprise-grade services and applications? SAP addresses this challenge with introducing the SAP Cloud Application Programming Model (formerly known as SAP CAP). SAP Cloud Application Programming Model removes the dependency on multiple platforms, thus focus on accelerated development and safeguarding investments in the rapidly changing world.
What is SAP CAP?
SAP Cloud Application Programming Model (CAP) is used to build cloud services within SAP. The SAP Cloud Application Programming Model is an open and opinionated framework of languages, libraries, and tools for building enterprise-grade services and applications. It leads developers through proven best practices and a great wealth of out-of-the-box solutions.
It uses Core Data Services (CDS) as an universal modeling language for both domain models and service definitions. However, in the real world, even a complex data model is not sufficient. A common business case require a business logic behind the model. The CAP framework offers Service SDKs and runtimes for Node.js and Java, offering libraries to implement and consume services as well as generic provider implementations serving many requests automatically. All this to make the implementation the easiest as possible.
![]()
On the top of that, SAP CAP Model provides out-of-the-box support for SAP Fiori and SAP HANA (HANA Cloud Database as the persistence layer). SAP offers a dedicates tools support provided in SAP Business Application Studio, Visual Studio Code and Eclipse. CAP model supports different synchronous protocols like REST, OData or GraphQL as well as many asynchronous channels and brokers like SAP Event Mesh, MQ or Kafka.
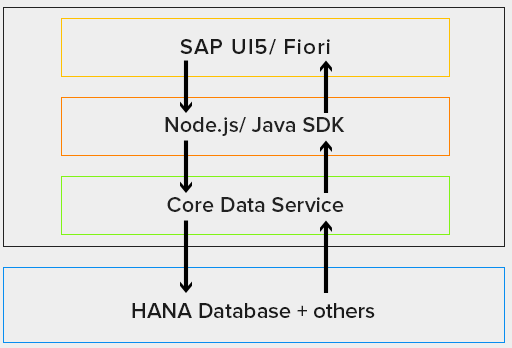
All of this is done in a smooth way, which requires minimal configuration. But despite of exposing of services, SAP CAP also provides a framework that allows you to consume other SAP BTP services in a seamless and safe way, therefore speeding up the whole process.
SAP Event Mesh is the default offering for messaging in SAP Business Technology Platform (SAP BTP). CAP provides out-of-the-box support for SAP Event Mesh, automatically and transparently handles many things behind the scenes. That makes the application coding agnostic and focused on conceptual messaging. This includes the following:
- Creation of queues & subscriptions for event receivers
- Handling all broker-specific handshaking and acknowledgments
- Constructing topic names (as expected by the message broker)
- Wire protocol envelopes (CloudEvents)
With a minimal effort, you can configure your application to consume messages as well as emit events to the specified queues of the binded SAP Event Mesh instance.
Use case
In the first article of this blog series by Andrzej you got an overview of how to expose your data in a fast and reliable way in real time using SAP BTP. In this scenario, every time a document is saved in S/4HANA system (in our case, this document is a Sales Order) the SAP Event Mesh distributes a message from S/4HANA to the integration platform (SAP Business Technology Platform). In consequence, an info about Sales Order with product details is saved in HANA Cloud database which is a persistence layer for a cloud-based service, which is a service build with SAP Cloud Application Programming model. As an effect, CAP service emits back an event to the SAP Event Mesh instance with information that order was saved in the database. An authorized user can access the data stored in HANA Cloud through CAP service at any time, from any place. You get an immediate notification with document info via messaging platform (i.e. Slack platform) using SAP Open Connectors. The API is securely exposed to the outer world by SAP API Management.
Summary
SAP CAP is a wise choice when you need to build enterprise-grade services and applications in a secure and open manner. The greatest advantage is the ability to use open-source languages and runtimes, including the capability to leverage third-party vendor libraries and the open-source community in general.
Read also:
1. Expose your data in a fast and reliable way in real time with SAP BTP
2. How to simplify your day-to-day operations with SAP Event Mesh
The post What are the profits of building cloud services with SAP Cloud Application Programming Model (SAP CAP) appeared first on INT4.
]]>The post About COALESCE, Left outer join, NULL and the link between them appeared first on INT4.
]]>In this article you will learn about:
- What you should bear in mind while joining tables in AMDP
- Usage of COALESCE function
Reading time: 5 minutes
Introduction
ABAP Database Managed Procedures (AMDP) – I guess everyone has already heard about it. It’s a powerful feature allowing ABAP developers to write database procedures utilizing code to data push-down approach. AMDP can significantly reduce the runtime of an ABAP program. There are also many other benefits but that’s not what this article is about. Today, I would like to pay attention to one possible issue as a result of left outer joins.
Recently, I encountered an issue in one of my AMDPs. I discovered that I’m missing some data in the result table. However, my missing data was visible in each of the joined tables. I double checked and confirmed that the data defined in the LEFT OUTER JOIN conditions was the same. However, the join didn’t fetch the data from the second table. I started to wonder, what caused the issue?
Left outer join – where’s the catch?
LEFT OUTER JOIN, by definition, selects the complete set of records from the first (left) table, with the matching records in the second (right) table.
Let us have a look at the following example:
Left table:
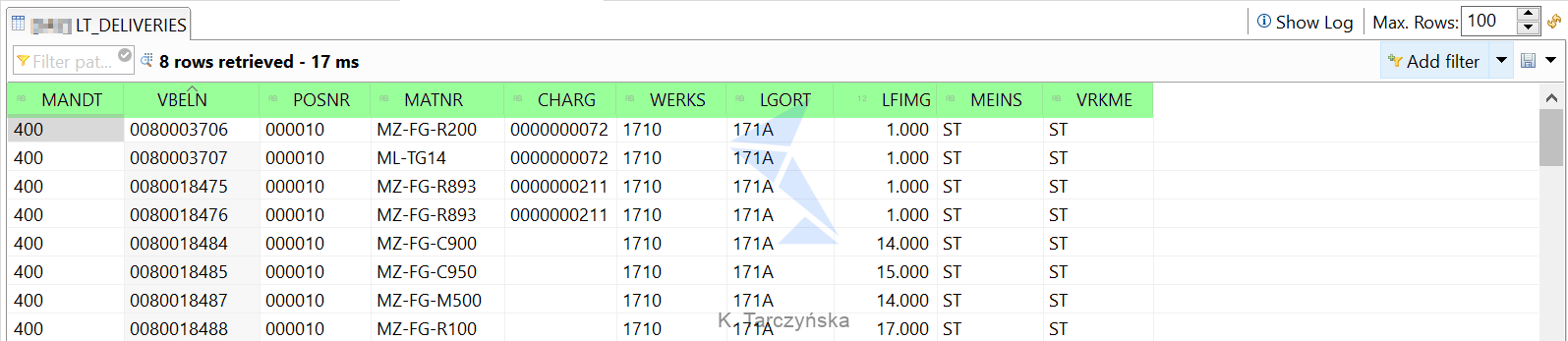
Right table:

Our goal is to fetch delivery data (left table) with information about batches (right table). We will join these tables on the following columns: MANDT, MATNR, CHARG, WERKS, LGORT. In this case, the left outer join statement in AMDP may look like this:
lt_deliveries = SELECT * FROM zdoc_table1; lt_batches = SELECT * FROM zdoc_table2; lt_del_batches = SELECT t1.mandt, t1.vbeln, t1.posnr, t1.matnr, t1.charg, t1.werks, t1.lgort, t1.lfimg, t1.meins, t1.vrkme, t2.ersda, t2.ernam, t2.lfgja, t2.clabs FROM :lt_deliveries AS t1 LEFT OUTER JOIN :lt_batches AS t2 ON t1.mandt = t2.mandt AND t1.matnr = t2.matnr AND t1.lgort = t2.lgort AND t1.werks = t2.werks AND t1.charg = t2.charg;
Result of the join (yellow fields were fetched from the right table):
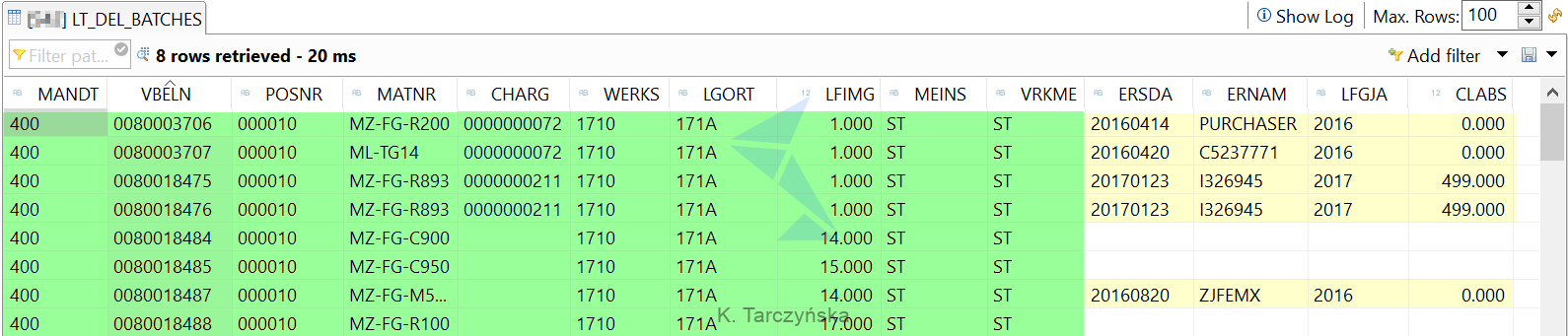
We got the correct results. Please note that HANA properly joined a row where one key column in both tables was empty (CHARG column – the last but one row).
Now, let’s focus on the problematic scenario.
In my case, I used similar left outer join conditions as in the example above (joined columns are marked in green).
Left table – LT_WITH_BILLING:

Right table – LT_ZDOC_DATA:

Here is the join statement and the result table:
lt_items = SELECT DISTINCT f.rbukrs, f.gjahr, f.belnr, f.docln, f.matnr, f.werks, f.prctr, f.ebeln, f.ebelp, f.aubel, l.txt, l.status FROM :lt_with_billing AS f LEFT OUTER JOIN :lt_zdoc_data AS l ON f.rclnt = l.mandt AND f.rbukrs = l.rbukrs AND f.aubel = l.aubel AND f.gjahr = l.gjahr AND f.belnr = l.belnr AND f.docln = l.docln;

Please notice that we’re missing data from the right table in the last two rows. How is that possible if the values exist in the LT_ZDOC_DATA table? The only possible answer is that values in some columns defined in the join conditions are not the same. Our first suspicion should be the AUBEL column. We already proved that it is possible to define joins over empty columns. Therefore, we may assume that at least one column (in either left or right tables ) has a null value. Null is not equal to empty – an empty string is a string instance of zero length, whereas a null string has no value at all. We can easily check our hunch by using IFNULL operator:
lt_items = SELECT DISTINCT f.rbukrs, f.gjahr, f.belnr, f.docln, f.matnr, f.werks, f.prctr, f.ebeln, f.ebelp, f.aubel, IFNULL( f.aubel, 'YES' ), l.txt, l.status FROM :lt_with_billing AS f LEFT OUTER JOIN :lt_zdoc_data AS l ON f.rclnt = l.mandt AND f.rbukrs = l.rbukrs AND f.aubel = l.aubel AND f.gjahr = l.gjahr AND f.belnr = l.belnr AND f.docln = l.docln;
Query result:

We guessed correctly! It is clear that null and empty strings are not the same and that’s the reason why we didn’t get the results from the LEFT OUTER JOIN. Let’s go back to the coding and check how the null was populated in our table:
lt_with_billing = SELECT d.*, f.vbeln AS vbeln_b, f.posnn AS posnr_b, f.erdat_b, f.erzet_b, f.fkdat_b, p.aubel, p.aupos FROM :lt_with_delivery AS d LEFT OUTER JOIN :lt_vbfa AS f ON f.mandt = d.rclnt AND f.vbelv = d.vbeln_im AND f.posnv = d.posnr_im LEFT OUTER JOIN vbrp AS p ON p.mandt = f.mandt AND p.vbeln = f.vbeln AND p.posnr = f.posnn;
The null value in AUBEL column for document 5000000010 was populated by the second join with VBRP table as there was no matching billing document.
Solution
How can we solve this problem? The aim is to join two tables where one column which is used as a join condition is empty and another column has a null value. It turns out that solution is fast and simple: COALESCE function.
A COALESCE function returns the first non-NULL expression from a specified list. Usually, we use COALESCE as one of the elements in the select list, however, it can be successfully used in the join conditions too.
Code with the COALESCE function:
lt_items = SELECT DISTINCT f.rbukrs, f.gjahr, f.belnr, f.docln, f.matnr, f.werks, f.prctr, f.ebeln, f.ebelp, f.aubel, l.txt, l.status FROM :lt_with_billing AS f LEFT OUTER JOIN :lt_zdoc_data AS l ON f.rclnt = l.mandt AND f.rbukrs = l.rbukrs * AND f.aubel = l.aubel AND COALESCE(f.aubel,'') = COALESCE(l.aubel,'') AND f.gjahr = l.gjahr AND f.belnr = l.belnr AND f.docln = l.docln ORDER BY rbukrs, gjahr, belnr, docln;
As you can notice, instead of f.aubel = l.aubel condition we used COALESCE(f.aubel,’ ‘) = COALESCE(l.aubel,’ ‘). In this case, when the f.aubel or l.aubel column is null, COALESCE will return a second value from the arguments list which is an empty string and HANA should properly join these two columns.
Result:

Summary
AMDP is a very powerful and useful development approach and as shown in this blog, we always have to be careful to get correct results. Even though in a debugger we can see that there is no value in the column, it can turn out that a null is hidden there and it can affect our final expected results. Fortunately this issue can be easily resolved with the COALESCE function used in the JOIN condition.
Personally I would like the Eclipse team to improve the table preview and mark null columns as a <null> value instead of displaying them as if they were empty strings. That would make the developer’s life a bit easier.
Read also:
2. Int4 IFTT – IDoc interfaces
The post About COALESCE, Left outer join, NULL and the link between them appeared first on INT4.
]]>The post Int4 IFTT – IDoc interfaces appeared first on INT4.
]]>In this article you will learn:
In this article you will learn:
- How to test IDoc interfaces with Int4 IFTT
- All the configuration required to test IDoc interfaces
Reading time: 5 minutes
Introduction
Int4 IFTT supports various interface types that can be tested in terms of SAP End-to-End testing. Synchronous and asynchronous, AIF, CPI, IDoc Interfaces and many more options to fill specific requirements. In this article, I would like to explain functional and technical details about testing IDoc interfaces using Int4 IFTT.
Int4 IFTT enables testing of standard IDoc interfaces as well as custom ones.
Configuration
In this section, I will show you in detail how to perform configuration steps required to test IDoc interfaces. The main step in the process is to create a Configuration (Automation) Object which is a
base object that stores all the rules for a single application interface to be tested.
We can divide IDoc interfaces into two groups depending on their directions:
- Inbound IDoc interfaces
- Outbound IDoc interfaces
The configuration looks very similar for both types. In this article, I will create a Configuration Object for an Inbound IDoc interface (IDoc ORDERS05).
Steps:
1. Navigate to Int4 IFTT Mass changes of configuration (tcode /int4/iftt_conf_mass) and click on the New Entries button. Enter object definition ID and description.
2. Provide IDoc details in the Service Interface Name column. Name of an IDoc interface should be a combination of IDoc message type, basic type and extension separated by a dot (.). You can find those details in the IDoc’s control record:
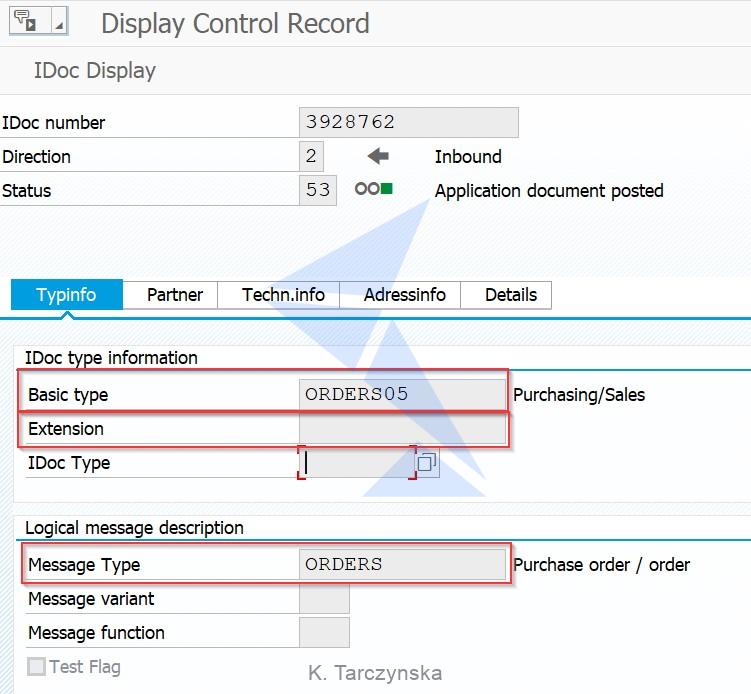
Therefore, in the above case you should enter ORDERS.ORDERS05 in the Service Interface
Name column, as below:

3. Navigate to the Variables section and define suitable variables. For our IDoc we need to define a variable for a Purchase Order number. Add new entry and provide Variable Name and Description and save your data:
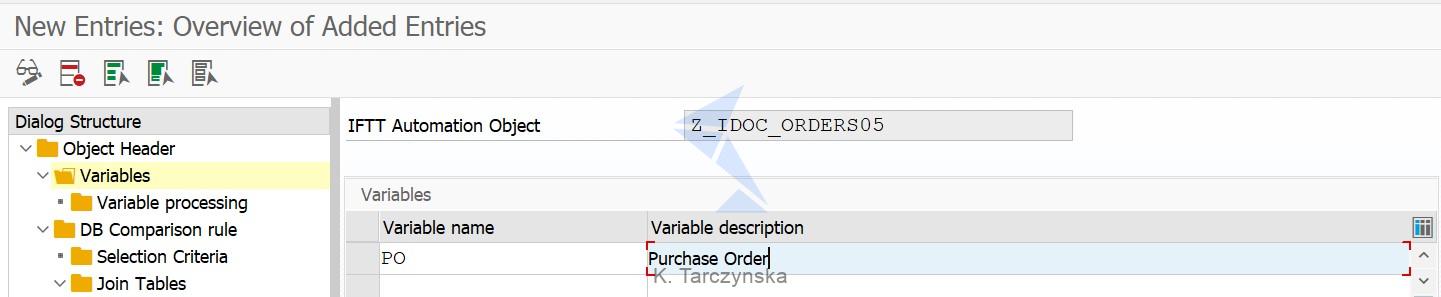
4. Next, select the line with the variable you have just defined and go to the Variable processing section. In this step we need to define how the variable should be processed by Int4 IFTT.
To find more details about Variable processing please follow the article of my colleague, Konstantinos Tsakalos – Int4 IFTT variables explained.
In our scenario, we define two actions for PO variable:
- Populate variable before execution with READ_MSG processor (to read variable from saved message). In the Processing Parameter column enter Xpath expression which points to the suitable segment with Purchase Order number in the IDoc
- Generate value for new message with NUM_RANGE processor (to generate new value and to substitute in the new message). Enter your variable name in the Processing Parameter column

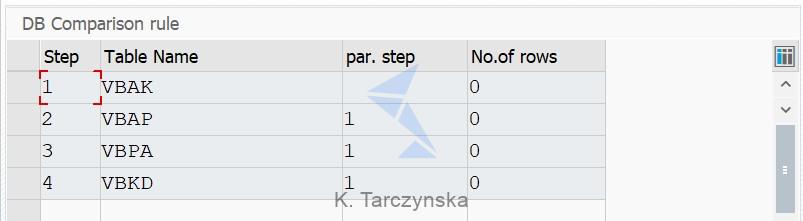
5. Our next step is to define Database Comparision rules. In INT4 IFTT you validate the actual posted data in the SAP database tables (or even custom ones) by comparing its database entries. You can find more details about Database Comparision rules in our recent Int4 Blog, here: Database comparison rule explained.
As we are testing ORDERS05 IDoc, our goal is to compare the final document which will be posted at the end of the process – a Sales Order. Therefore, we need to compare tables connected to Sales Orders (for example VBAK, VBAP). Add tables which data you wish to compare. The tables are processed in sequence based on Step number.
6. After populating the table names with the additional parameters, save your entries, select the table you want to configure and double click on Selection Criteria. In our example, we want to fetch the data from table VBAK based on BSTNK (PO Number) field. We will use PO variable which will contain the actual test case PO number (that is the variable we defined in Step 3.).

Define Selection Criteria for the rest of your tables. For VBAP table we need to fetch the data based on the actual database values of the parent step. We will reference to the VBELN field of the Parent Table (VBAK). In this case, the criteria should be set as follows:

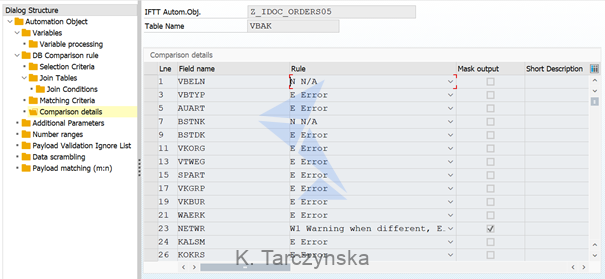
7. Select table from DB Comparison rule section and navigate to Comparison details. Now you define table fields which should be compared during test execution. You can define a Rule which would be applied when compared data is different or empty. Sample data for VBAK table:
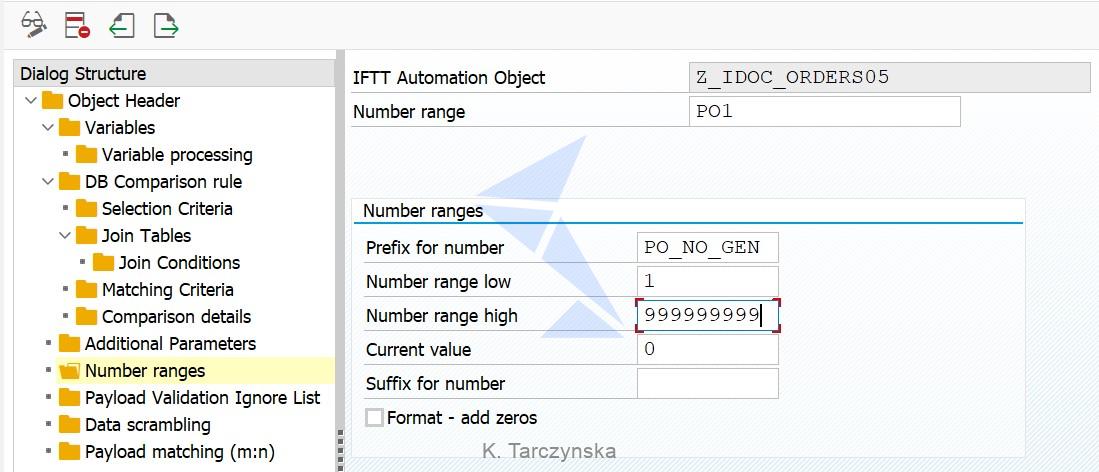
8. Our last step is a definition of the Number range used in Step 4 – as we used option to Generate value from number range. Enter the Number range name (we used PO1), specify a meaningful prefix and define low and high values. Save your data.
After completion of the above steps we are ready to test our IDoc interface. It is possible to define additional steps like Matching Criteria/Data scrambling rules and few more – you can find information about these options in our blogs.
Test Case creation
To test an Interface, we need to create a test case. Go to the Int4 IFTT Cockpit (tcode/int4/iftt_tcockpit) and switch to Edit mode. Navigate to the desired folder and add new test case.
Fill in Test Case details: description, Interface Type (6 for Inbound IDoc and 7 for Outbound IDoc) and enter the Configuration Object name you have created in the previous section. At last, we need
to specify an IDOC number of the original IDoc which was already successfully processed and posted in Backend:

Save and execute your test case. An execution report will be displayed:
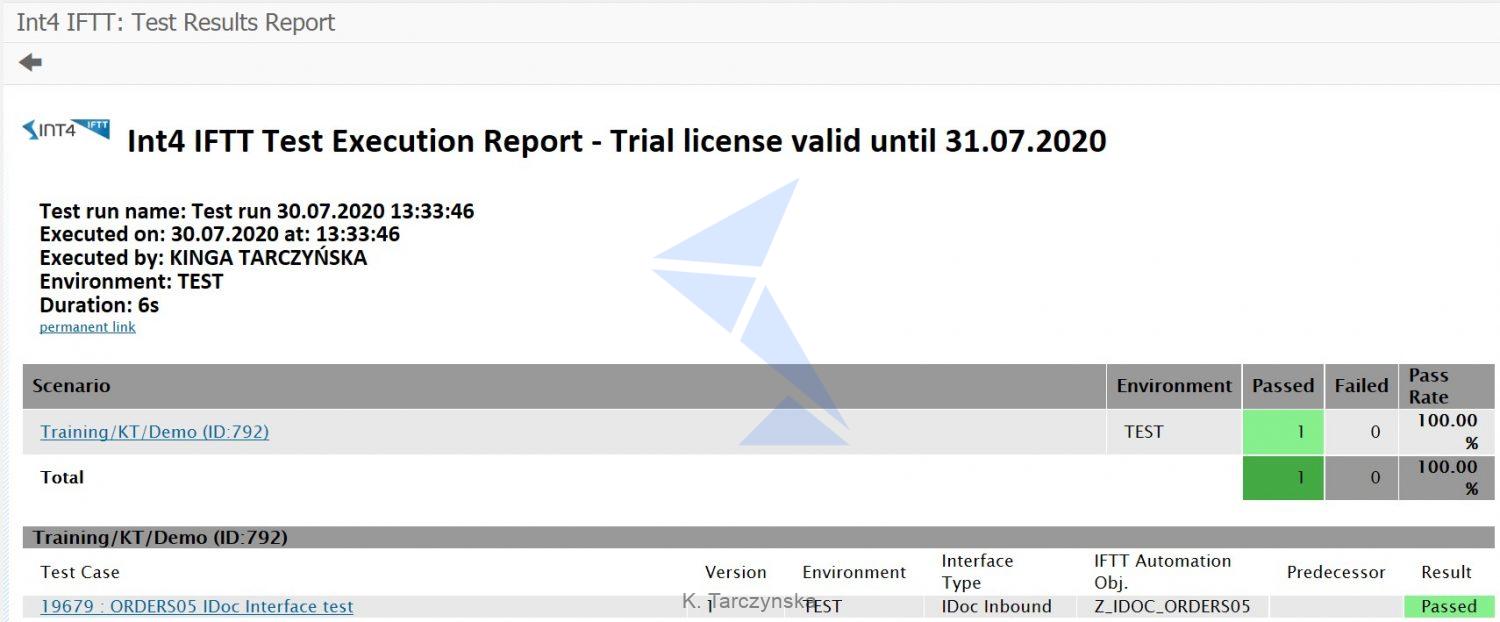
You can display detailed execution report by clicking on the Test Case name. SAP Backend Document validation will be displayed with the database entries comparison (for the original IDoc and the newly created one during Int4 IFTT test):
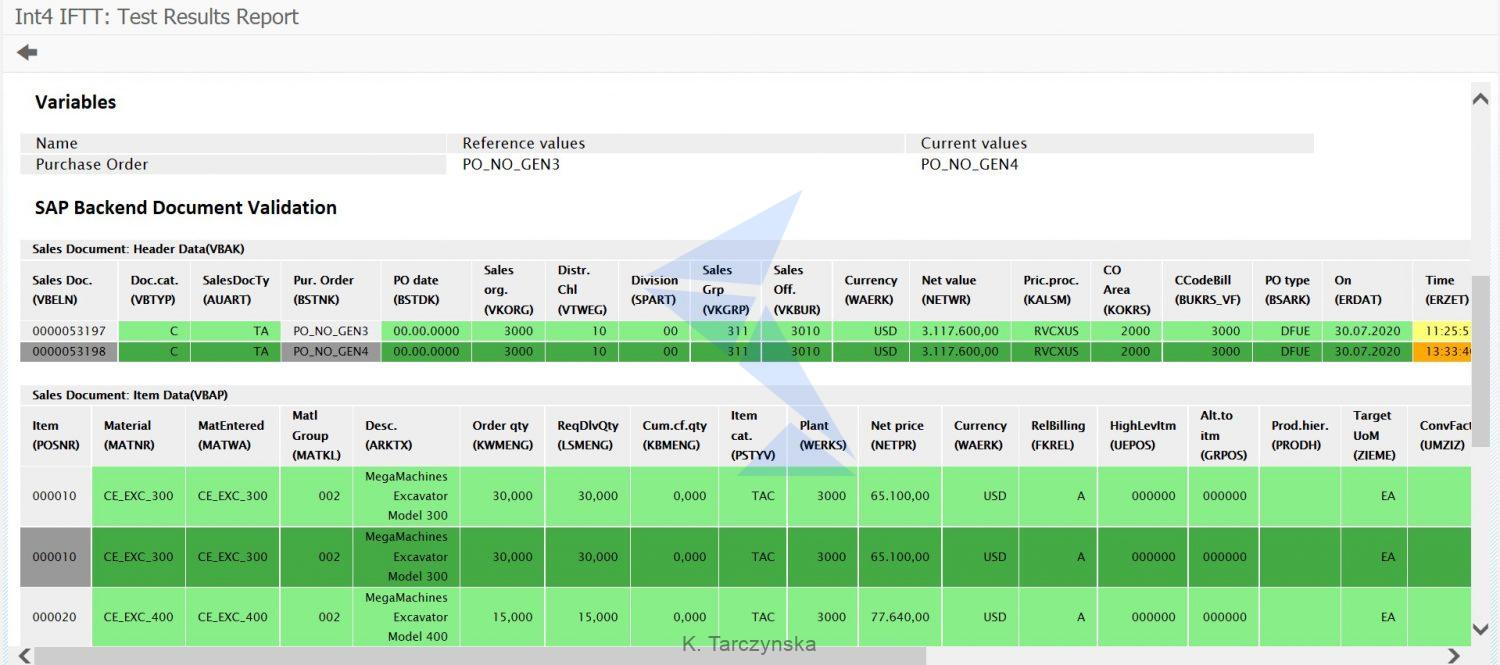
Summary
I hope with the help of this blog, you will be able to test your IDoc interfaces quickly and effectively. Since Int4 IFTT tests is based on comparing entries in the database, we can easily add custom tables to the configuration or even test a completely custom IDoc processing. Do not forget to check out the rest of our Int4 blogs and learn more interesting features of Int4 IFTT. If you want to find out more about this (or other) Int4 IFTT features, just book a consultation with the product demo or contact us.
The post Int4 IFTT – IDoc interfaces appeared first on INT4.
]]>The post GDPR in Int4 IFTT – data protection in testing appeared first on INT4.
]]>In this article you will learn how to:
- Protect production data during testing in Int4 IFTT
- Run your tests in compliance with GDPR
Introduction
The reliability of application testing results depends largely on the extent to which test data corresponds to production data. It would be best to do the tests under the same conditions as they occur in the business process and on the actual data in the company’s resources. In Int4 IFTT those conditions are met – test cases can be created based on the message that was already successfully processed in a productive environment.
But somebody may think – wait, what about GDPR (General Data Protection Regulation)? According to GDPR requirements, companies may not store or use personal data without the express consent of the person concerned. At the moment, you may ask yourself:
- How to reconcile reliable and solid tests with GDPR?
The best solution would be to perform tests with data as consistent and similar as possible to production data in a way that no GDPR rights would be broken. With automated testing tool, Int4 IFTT, you don’t have to worry about it as we are providing anonymizer feature to fill this gap.
Data Scrambling in Int4 IFTT
As mentioned in the previous paragraph, Int4 IFTT offers a functionality called message selector thanks to which you can quickly select test case data from PI/PO or CPI system without need of logging into it. Let’s assume your goal is to perform regression testing of the actual production data. Therefore, if the value is sensitive in terms of privacy or GDPR requirements, we would like to prevent the value from being stored and displayed in Int4 IFTT execution report.
Thanks to Int4 IFTT’s anonymizer feature, we can select fields which hold sensitive values and decide what action should be taken to prevent it from being compromised. Data scrambling rules are set on Automation Object level.
Procedure
To define data scrambling rules, open Int4 IFTT Mass Changes of configuration (transaction /INT4/IFTT_CONF_MASS). Select the required Automation Object and go to the Data scrambling section.
There are two rule types available:
- Test Case Creation – in case you want to scramble data during creation of a test case
- Runtime – in case you want to scramble data during runtime – when the interface is executed and additional data is loaded to test case data.
In my case, I want to protect the client’s personal data, i.e. name and address which are visible in the content of a test case:
You can decide what action should be taken to prevent it from being compromised. You can replace it with a constant, generate a GUID / random/hash value or mask it with a specific character. There is also an option to implement a custom method to meet specific scrambling criteria.
Next, specify a path that points to the field/node where the exception should be applied. It can be an xpath expression for an XML file (as in our case) or Int4 IFTT Flat File syntax for flat file formats.
In my example, I will mask each character in the name, street, and postal code with “X”. Furthermore, I’ll replace the original city with a constant value and generate a hash value using the SHA1 algorithm for the state.
Now, if we create a new test case with this automation object data scrambling rules will be applied. Result:
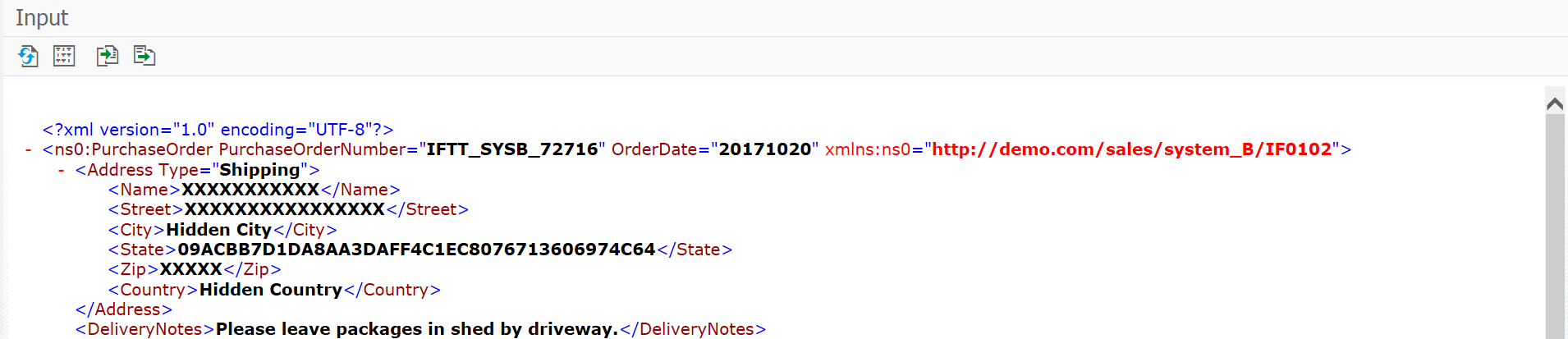
As you can see, sensitive data is not visible anymore. With Int4 IFTT anonymizer feature you can also hide data in the reference and current execution message (payloads) in a test results view:

Summary
With the Int4 IFTT anonymizer feature, you are able to prevent the value from being stored and displayed in the Int4 IFTT execution report. Therefore, you can perform regression tests based on successfully processed messages from your productive system without the risk of breaking GDPR regulations.
Read also:
- Import and Export Test Cases with Int4 IFTT
- SAP Process Orchestration (SAP PO) support extended till 2030!
The post GDPR in Int4 IFTT – data protection in testing appeared first on INT4.
]]>