The post The “big ideas” of today really are mostly very late realisations of the ideas from half a century ago. appeared first on INT4.
]]>Let me introduce my guest
My today’s interlocutor transfers customers’ thoughts into the source code and has been involved in the SAP industry for over 15 years. He specialises in database-related matters and loves to solve unsolvable problems.
About Machine Learning in the SAP industry, the differences between On-premise & Cloud solutions, and his adventure with SAP PRESS Book – Lars Breddemann is interviewed by Jarosław JZ Ziółkowski.
Reading time: 9 minutes
1. You work as a senior data management and analytics expert. Thus, I need to ask: what exactly your job is?
In short, my job is to know how to work out what the client wants and needs and how to implement those requirements. Often, I get pulled into an implementation project where there already exist data and code, and the question is how to make the process faster or more scalable.
The thinking here is “oh, we just need a little HANA-magic-tuning-dust to be sprinkled over the solution”. That, sadly, is not how things work in real life. When I work on a solution, I find the bottleneck and the reason for why this bottleneck exists. If it turns out that certain parts of a process do not need to be done, or they can be performed much less often, then this can be a quick win for performance and scalability.
For example, I had to optimise a big financial analytics process and found that certain “master data” lookup values were re-computed every time the process was executed. By changing the solution to compute and store the values upon data loading time, I was able to remove this part of the code and save a lot of CPU time and memory – which are the primary resources for HANA.
Upfront, it was not possible to know that this would be the solution or by just looking at some performance trace. The primary developers had looked at this issue for months and could not figure it out. Instead, it was necessary to deeply understand what each part of the process is meant for and how it contributes to the performance. Performance optimization is just one part of my job. I also help development teams by picking the best way to implement a certain functionality on their data platform. Often, frontend- and API-/business logic developers don’t have a good overview of what tools a platform like HANA provides, and even less often they can evaluate which tool would be the best choice for a given task.
That is not the fault of those developers. After all, how can one single person stay on top of the whole development stack, where every layer has X components, and each of those components gets bi-monthly major updates? That’s where I help with the data processing layer. So, I’m probably not the best person to talk about the frontend framework, but I’d say I cover HANA and databases rather well.
2. Continuing, please tell me which departments do you work with most often?
Most often it’s analytics and data science teams that have their data in one or many databases and want to implement their solutions with it. Usually, this starts fairly easy, but once the reports, dashboards, and insights become important to the business parts of the solution may not hold up too well. Sometimes “big” queries use up all memory and render the HANA instance blocked for others. Sometimes the daily data loads do not fit in the allocated window anymore, etc.
This usually is because the analytics teams are focused on delivering the right semantics with their products and basically they have to trust the platform that it will deliver the required performance. There really is no good tooling for analytics and data science users to learn how their code/models perform and how to scale it easily. All that is available are DB/HANA expert tools.
My role is knowing both sides of this chasm and enabling a feedback loop that eventually leads to a better solution. And this is precisely what I offer with my company Data Process Insights. Getting analytics right, both on the semantic and the technical level, so that users, in fact, can learn useful and meaningful things from their data and make data-driven decisions.
3. That sounds interesting, especially concerning my next question. You write about yourself that you have extensive experience in solving difficult problems. So, what challenges do you face at work?
Okay, so one person’s “difficult” is the other person’s “bread-and-butter”, but if the core developers and lead architects of big data products struggle to make their product scale, then that is the kind of problem I tend to work on. Then again, the challenges could be not-technical in nature.
When I worked with SAP Health, many potential customers wanted to test-drive what the solution could do for them before making a major investment. The SAP Health platform was a clinical data warehouse for millions of patients’ data and thus very sensitive in terms of data security. As the platform was not designed as a SaaS solution, such a test drive would have required their own HANA server, that is too expensive, or cloud VM which is not acceptable for data security reasons.
The solution I came up with was to create the HANA-in-a-box instance that had the whole solution in a pre-configured VM running on a local Intel NUC machine. This guaranteed minimal deployment times and maximum control over the data by the clients. They could literally take the HANA system home and physically put it into a safe if required.
4. But you used to work as well for SAP for over 15 years, going through different positions in different countries. I’m wondering which of those countries do you remember most, and of course, why?
I started to work for SAP in Vienna, Austria, which is a great city. I met many good friends there and am looking forward to the time when we can travel again. Because of COVID, there’s no travelling from Melbourne and Australia right now.
After living there for about 12 years, I moved back to my hometown which is Wuppertal in Germany since my work at that time focused mainly on international clients, and so I used that as an option to spend more time with my parents and old school friends. That was great, too.
And then, I met my partner and moved in with her straight to Melbourne. Well, Melbourne and Vienna share the same fame in having “won” the title of “most liveable city in the world” a couple of times, so I cannot really pick a favourite here. However, where we live now, I just have to cross the road to get to the sandy beach – that’s hard to beat.
5. We already know that you used to travel frequently. Still, it is also worth mentioning that you are a co-author of the book “SAP HANA Administration”, and a prolific blogger as well. Why are you so willing to share your knowledge and when will we see your new book?
Writing and publishing the book quite simply was a life-goal for me, and I guess my co-Author Dr Richard Bremer had a similar view. When we wrote the book in 2013/14 the state of SAP HANA documentation was not great, and there was no proper reference book available that we could refer our customers to. What we wanted was a book that would explain core concepts on a level that makes sense to the DBA or HANA user, and that would enable them to use it effectively. We got lucky by getting a fantastic editor from SAP Press, a big shout out to Kelly Grace Weaver, and the book fared really well. More than six years later, it’s still being bought, which is astounding to me. It’s such a niche topic, and the product moved on a lot since then.
A new book is currently not in planning. We have been asked a couple of times about writing a new edition. Personally, I would rather write a different book altogether instead. Writing my blog or answering questions is dear to me. When I started working with databases, the documentation was still in the form of thick paper-reference binders. It was hard to get answers to problems quickly. Years later, I discovered websites like AskTom from Oracle, where questions were answered straight on, including the concepts that stand behind the answers. This made a huge impression on me.
Then, working for SAP, I joined SDN, an ancestor to SAP Community, and started to answer questions myself. After a while, I wrote a first blog post, and everything else followed from that.
With my blog posts, the main reason for writing usually is that I want to work through a topic for myself and not lose it afterwards. So I write it up and publish it. Thanks to google, I can now search for my old articles if I fail to recall specifics.
With answering questions, mostly on SCN and Stack Overflow, my main benefit is that many of those questions do not have obvious answers or present problems that are not typical for SAP environments. Getting “strange” questions is an excellent way to broaden the horizon and to check your own assumptions and knowledge.
6. Since you are on friendly terms with “HANA topics”, I’d like to know why SAP HANA is unique from your point of view?
The fundamental idea behind SAP HANA is to pack the majority of data management capabilities, an SAP customer from any industry would need into a single platform. Running the transactional ERP system on the same platform as the operational reporting, the data science-driven customer analytics as well as geospatial computing, and machine learning.
This “all-in-one” approach takes away many challenges that come with operating separate systems away and allows users to use another feature when they need it. For example, if you want to use special functions to process hierarchies or network data, then there is no need to install another product for that.
7. As far as Machine Learning is concerned, I assume that it is not a new concept for you. How do you think this area can be used when it comes to ERP systems?
The extent of what the majority of users do with their computers is frustratingly little. As Alan Kay demonstrated at OOPSLA in 1997 – that’s 23 years ago, longer than my whole professional career – “The computer revolution hasn’t happened yet”. While everybody in the well-off countries now has access to a global knowledge and computing network, the ability to use this and to learn and discover new things by using it has not progressed.
Much of organisational computing is still done on a simplistic Excel level. You know, sort
and filter data, maybe a VLOOKUP or pivot table for the power users and that’s about it.
I guess that this is partly because better methods are still too technical for the non-scientific, non-coding users and partly because there is a steep learning curve. Finally learning per se is an investment, and somebody has to pay for that. Now, as an organisation, I can either go and try to train my workforce in general methods, and the special applications that are relevant to their respective role. Or… I can teach a machine to do a specific job automatically.
Think of an automatic(“machine-learned”) travel expense claim approval system. Or having the system propose the next step in a complex process, based on how that process has been done in the past without writing much code that needs to be managed and updated. If successfully applied, such solutions automate such jobs and the person that used to do it, is now free to focus on the tasks that require more knowledge, experience, and decision making than the “dumb” part that was automated. All in all, the Machine Learning we’ve seen in the past decade or so, is about the automation of pattern recognition – basically, it’s programming by example instead of code.
8. Okay, so the question that arises to me is, what is learning SAP machines? And for which industries can it be of use?
SAP’s offering in the Machine Learning space has been a mixed bag in the past.
Some parts of it are built into the SAP applications, like SAP Concur, SAP Hybris, or the various planning solutions. Other parts are pure technology offerings, like the HANA ML APIs/Libraries.
The former solves a specific function for SAP users. At the same time, the latter opens up the SAP data stored in HANA to a broader set of technology commonly used by data scientists and data analysts.
9. Last but not least, On-premise or Cloud? Which of these solutions would you choose?
To me, the answer to this question is mostly about managing costs for a solution. How much and when will I have to pay for a given solution or part of that solution. And also what quality of service can I get out of this?
Running your own IT infrastructure can easily become a person-intensive and upfront cost heavy task that, in itself, rarely helps to make money. To many organisations, IT is still seen as a cost centre and associated with “taking care of the servers”.
Beating the costs and quality of service of any of the cloud providers is hard and probably not something most companies should want to invest into – that’s why in my mind using a cloud-based operation is the default choice when the organisation has at least some experience with it.
With SAP customers, the situation is somewhat special due to the fact that many of them have already done massive on-premise investments, both in hardware and staff, which makes those investments “sticky”.
A good analogy probably is to see how industrial power changed from something that would be generated on-site in or near the factory, and that is now routinely simply consumed through the public power grids.
This is the exact idea that John McCarthy explained in 1961, I mean, computing as a utility. It’s kind of disappointing to see that the “big ideas” of today really are mostly very late realisations of the ideas from half a century ago – especially for an industry that claims to be the innovation motor.
Read also:
1. Autonomous system such as Tesla autopilot could be a future of the ERP
2. SAP Application Server is like Arnold Schwarzenegger in the Commando movie
The post The “big ideas” of today really are mostly very late realisations of the ideas from half a century ago. appeared first on INT4.
]]>The post I want it all and I want it now! Smart Data Integration (SDI) – Initial Load and Real-time Replication appeared first on INT4.
]]>Introduction
One of the most common situations during the data replication process is that we have two (or more) systems and we need to constantly replicate existing and newly created/changed data from one to another and then track all the changes in all these available systems.
I think that immortal Freddie Mercury actually dreamt about an initial load and real time data replication.
Example of Realtime Flowgraph
We create a flowgraph that will be working in the Realtime mode. For this particular example, we will use a single HANA instance.
First of all, we create two Remote sources using HanaAdapter for source and target tables.
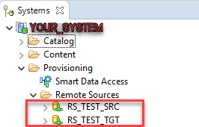
Then we create test database tables:
- source
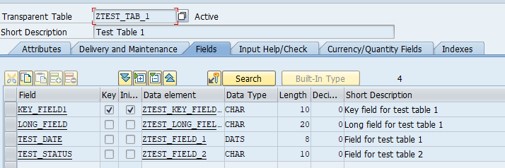
- target

As we already have created test database tables we should create corresponding virtual tables in our schema TEST_SAP_2_ORA:
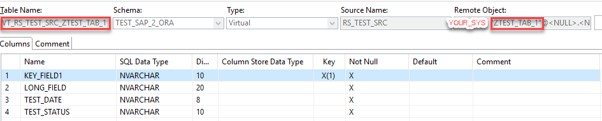
Flowgraph creation
Next, we go to SAP HANA Web-based Development Workbench Editor and create a Flowgraph:
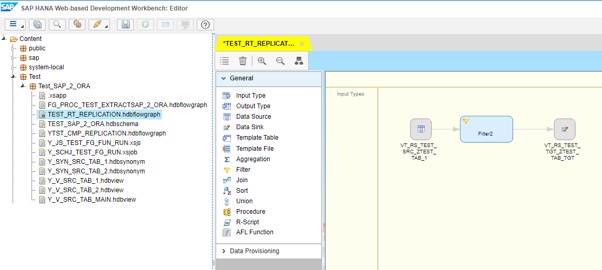
To set Flowgraph as Realtime we should mark a corresponding checkbox in source table:
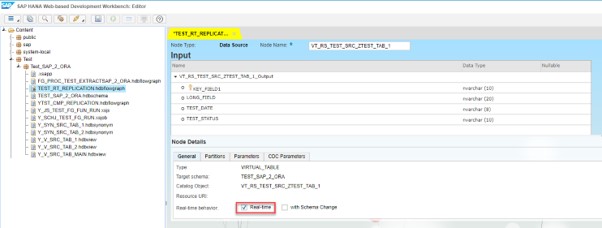
Keep in mind that we can have only ONE table per flowgraph marked as Real-time.
In Filter node we will create and map field CHANGE_TYPE:
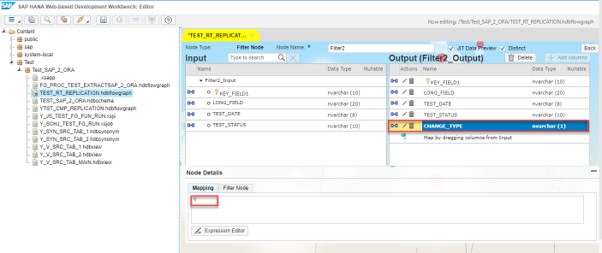
In Data Sink node define Writer Type according to our needs. Then save and activate the Flowgraph.
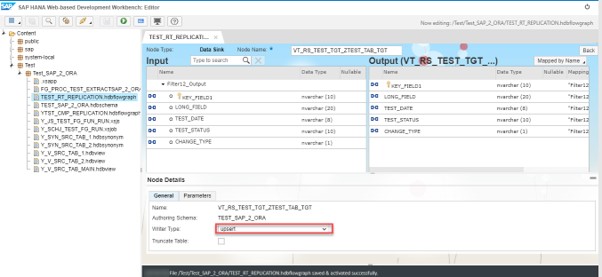
In order to simulate the initial load we just Execute the Flowgraph and control the values in the target table.
In source table we have the following set of data:
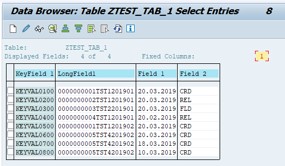
After initial load we see in the target table the same data with mapped Change Type:
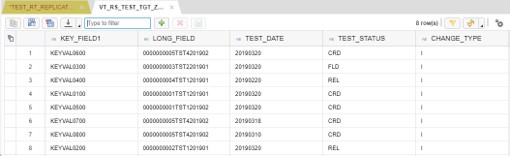
Now we need to proceed with Realtime replication by adding another entry to the source table. By saving the entry we assume to have automatically created an entry in the target table.
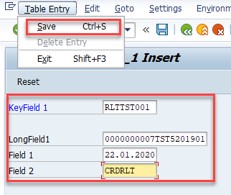
As we see, a new entry appeared in the target table automatically.
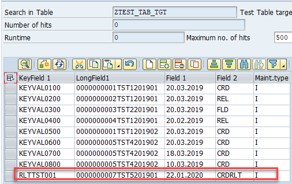
The basic principle of Realtime replication is trigger-based processing. For the user executing the Flowgraph system generates a set of triggers that track any changes (Insert, Update, Delete) in the source table and then update the target table with corresponding data.
The above-presented design is just an example that fits the purpose of sending data from one table to another with updates reflected as inserts. With the flowgraph palette, you are able to create other designs that would fit your specific scenarios.
Thank you for your attention. In case you’d have any questions about SDI please feel free to comment under the blog.
The post I want it all and I want it now! Smart Data Integration (SDI) – Initial Load and Real-time Replication appeared first on INT4.
]]>The post Smart Data Integration (SDI) – transporting SAP HANA objects appeared first on INT4.
]]>Implementation procedure
The standard implementation procedure usually consists of such steps as development, quality assurance and production go-live.
After all the activities performed in the previous blogs, we need to find out how to move all our HANA development objects in further systems according to your transportation schema.
For this particular reason, we have so-called procedure of Synchronizing SAP HANA Objects and Packages with ABAP.
As a prerequisite, the person responsible for synchronization of SAP HANA Objects with ABAP should have the authorization in role SAP_BC_DWB_ABAPDEVELOPER plus transaction authorization for Tcode SCTS_HTA.
A step by step guide
The whole process will consist of the following steps:
1. Call transaction SCTS_HTA in your ABAP system.
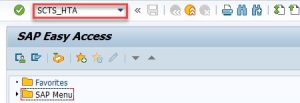
2. Using a search help select one or more SAP HANA packages. If required, mark checkbox Include Subpackages.
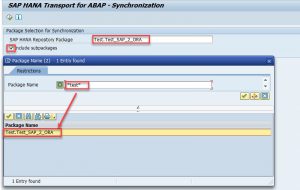
3. Pick the objects to be synchronized and transported.

Keep in mind that you should be careful with the objects you selected. Consider only those which need to be in the further system. Try to avoid transporting of objects created for test purposes.
4. After pressing F8 optionally we can deactivate the translation relevance for SAP HANA packages.
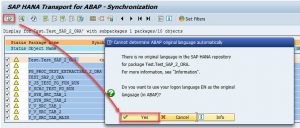
By default, the texts of SAP HANA objects are synchronized in the original language of the SAP HANA package and are then available for translation. If you do not need a translation, you can deactivate the translation relevance.
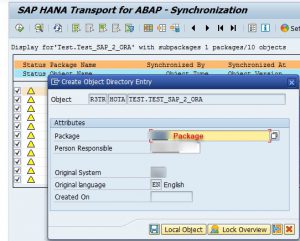
5. Define the Package for objects to be transported.
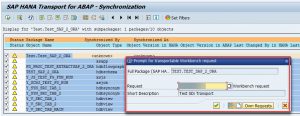
6. Provide corresponding Transport request:
7. By pressing the save button, all selected objects are synchronized and added to the Transport Request, their status is changed to green. It means that the system reads the currently active versions of the selected packages and objects from the SAP HANA repository and writes these to the HTA repository (in ABAP). The system adds transport objects for the synchronized packages and objects to the selected transport request.
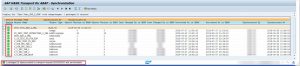
Here you can see the content of the Transport Request:
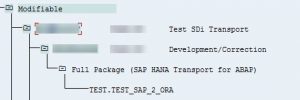
To import the transport request into the follow-on systems, release it.
Thank you for attention. In case you?d have any questions about SDI please feel free to comment under the blog.
The post Smart Data Integration (SDI) – transporting SAP HANA objects appeared first on INT4.
]]>The post Smart Data Integration (SDI) flowgraph data processing appeared first on INT4.
]]>FG_<RuntimeBehavior>_<SubjectArea>_<action>.hdbflowgraph
|
Runtime Behavior |
Suggested Naming Convention |
| Batch Task | BATCH |
| Procedure | PROC |
| Realtime Task | RT |
| Transactional Task | TRANS |
For example when our task is to extract test data from SAP to Oracle using a procedure our flowgraph would be named as follows:
FG_PROC_TEST_EXTRACTSAP_2_ORA.hdbflowgraph
Development workbench provides a wide range of instruments to organise your data flow so that your target requirements are met:
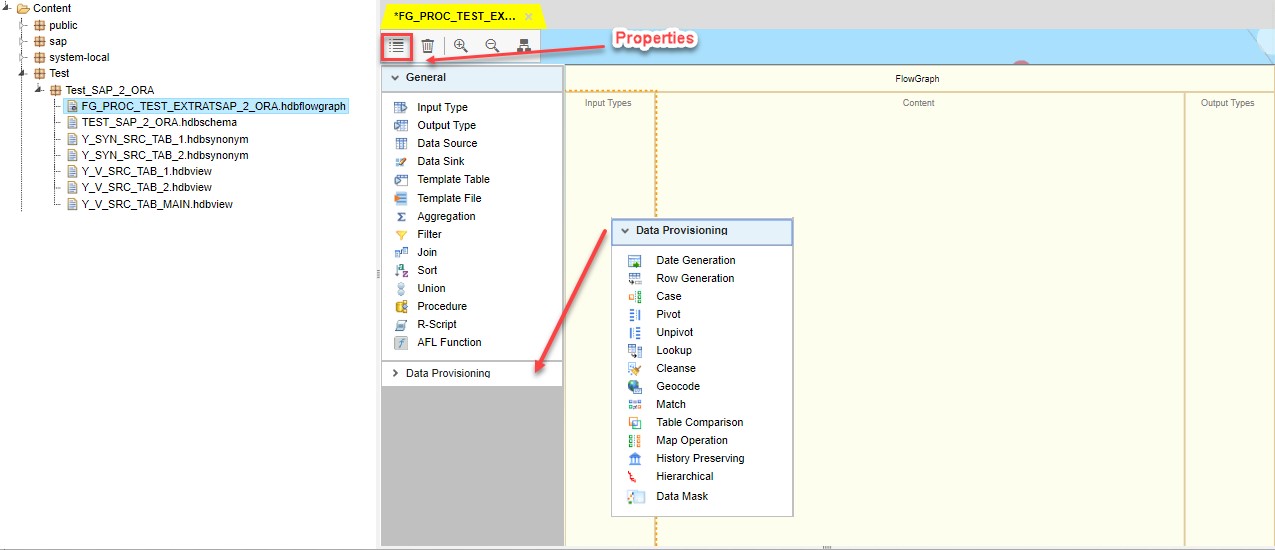
At first we fill in the flowgraph’s properties:
- Assign Target schema
- Select corresponding Runtime Behaviour Type
- Data Type Conversion (if needed)
- Create local variables
- Provide partitioning settings in case of big volumes of information are replicated.
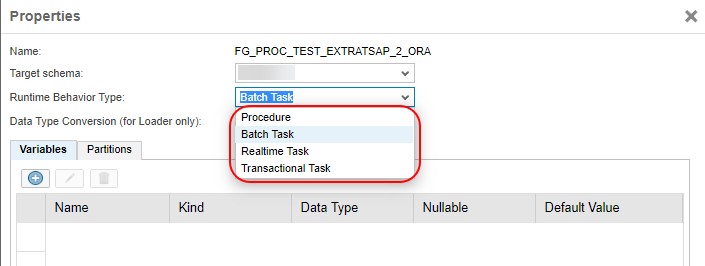
It is rather difficult to cover all the available options in one post. We will use the most common ones for the demonstration of a flowgraph object.
Firstly, I put in the content area a Data Source. It will be the main hdbview, which was previously created.

Then we will add Aggregation block and connect it with Data Source with an arrow:
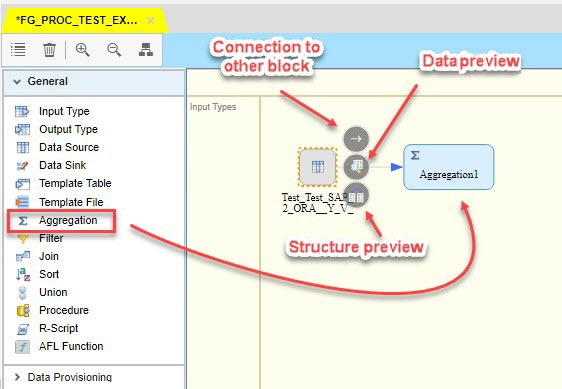
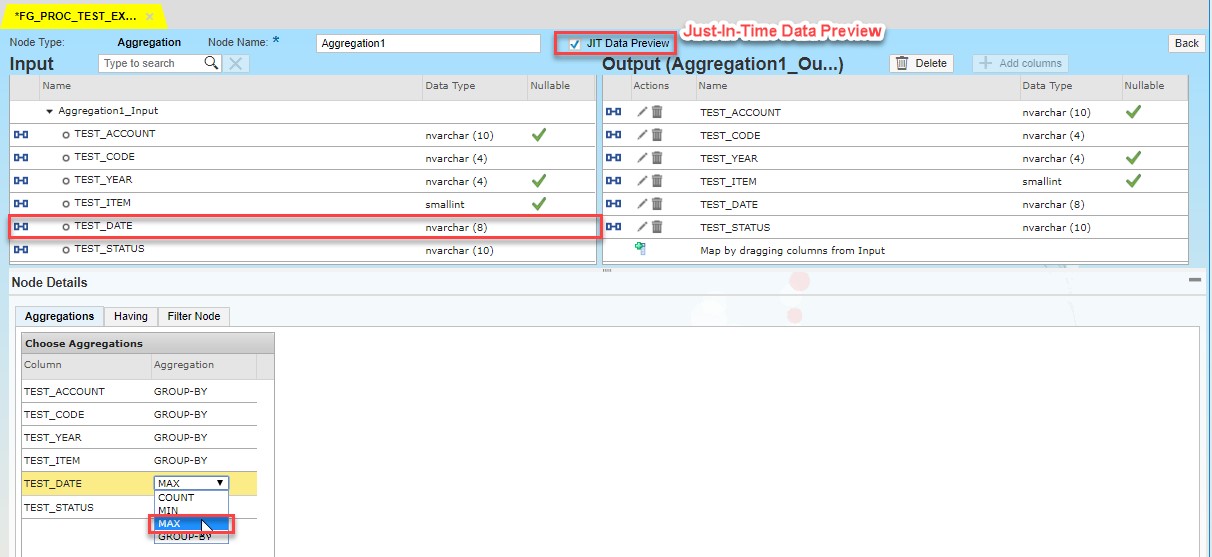
In this block we will aggregate entries with use of MAX function applied on a “test_date” field in order to exclude old data from the set. I would like to mention a very useful feature – JIT Preview, which allows us to check data set on each block where the feature is enabled. Having clause and filtering could be also provided in the aggregation.
The next block is Filter:
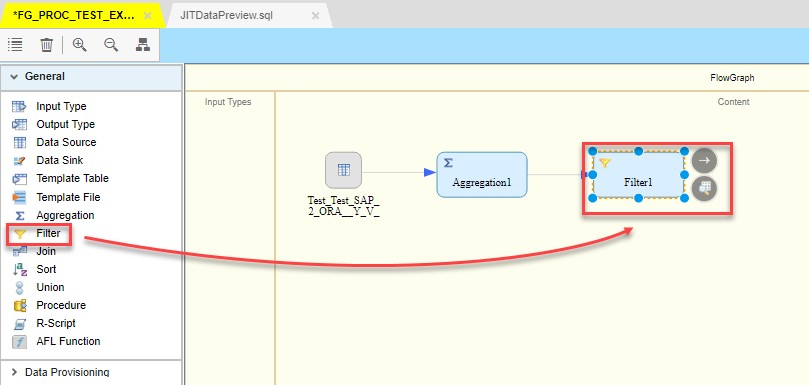
This block allows to put the fields in different order, create or remove fields from the source set. We need to create two additional fields for the view in this case. These fields are:
- CHANGE_TIME – Displays the time stamp of when the row was committed. All changes committed within the same transaction will have the same CHANGE_TIME;
- CHANGE_TYPE – Displays the type of row change in the source. The following values are available:
| I | INSERT |
| B | UPDATE (Before image) |
| U | UPDATE (After image) |
| D | DELETE |
| A | UPSERT |
| R | REPLACE |
| T | TRUNCATE |
| X | EXTERMINATE_ROW |
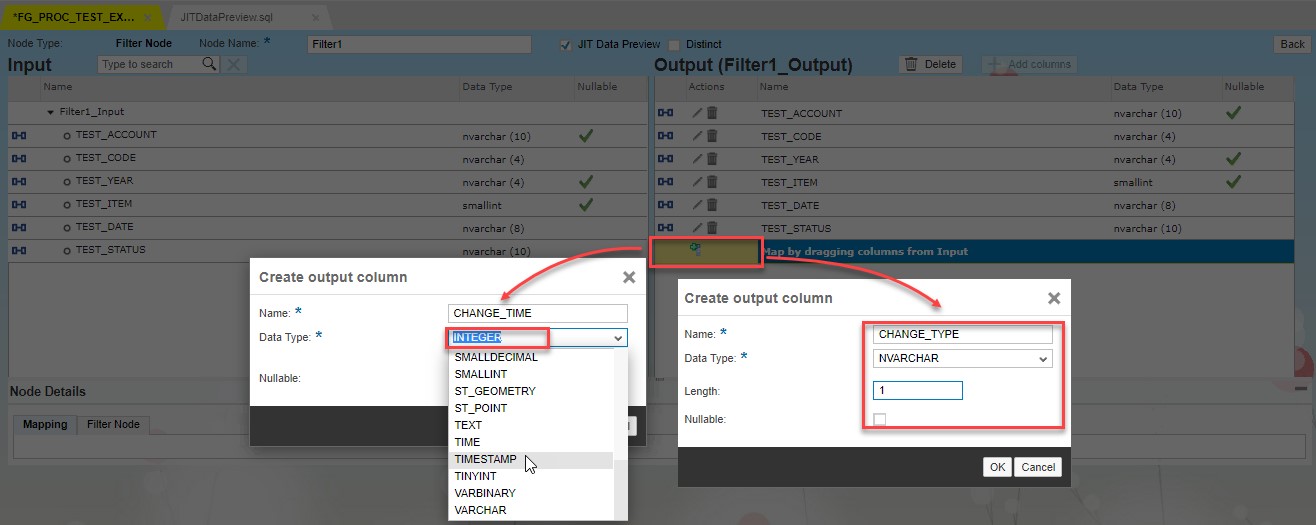
The value for CHANGE_TYPE in the mapping field should be ” ” and for CHANGE_TIME should be CURRENT_TIMESTAMP or CURRENT_UTCTIMESTAMP. You can also provide additional filtering statements here.
In order to check the correctness of the data that we move we use an element called Template table.

This block will play the role of target ORACLE table. It automatically creates the structure which was passed after Filter.
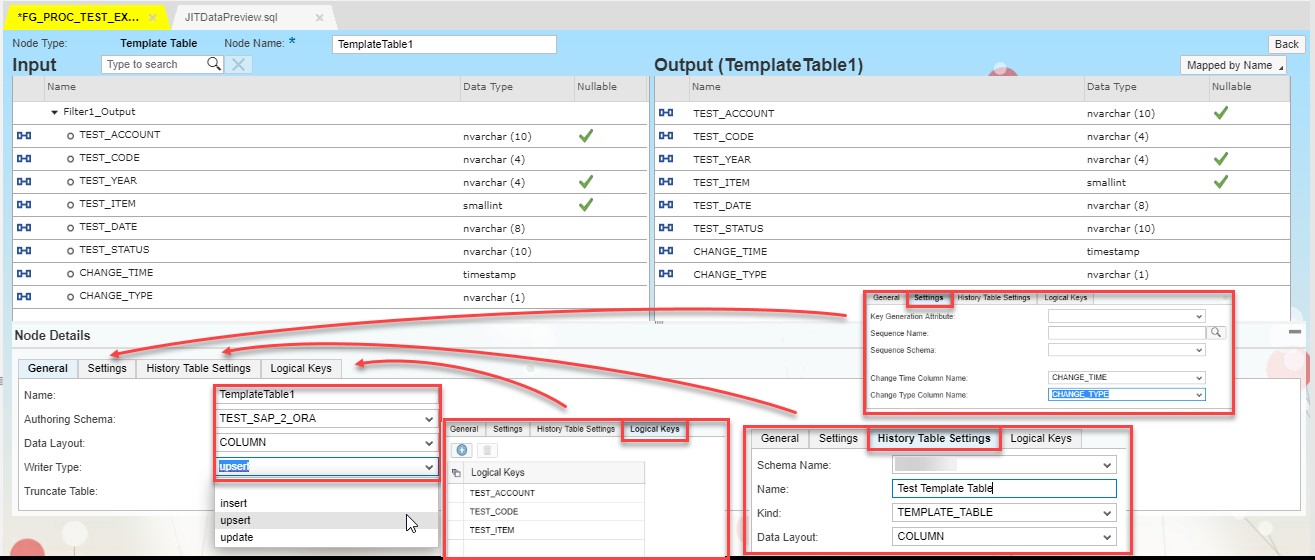
In Node Details we have to provide all necessary data. In General tab we should put:
- The name of the Template Table
- Authoring schema
- Data layout
- Writer type (In our case we will pick UPSERT)
- Checkbox Truncate Table allows to clear all data in the table before new entry.
Settings tab allows to set:
- Key Generation Attribute
- Sequence Name
- Sequence Schema
- Change Time Column Name
- Change Type Column Name
History Table Settings tab:
- Schema Name
- Name of the table
- Kind of the table (TEMPLATE_TABLE or DATABASE_TABLE)
- Data Layout (RAW or COLUMN)
In Logical Key tab by pressing “+” sign you can set key fields.
After saving the flowgraph the system generates in the Catalog new TemplateTable1 which we just put in the Content area.
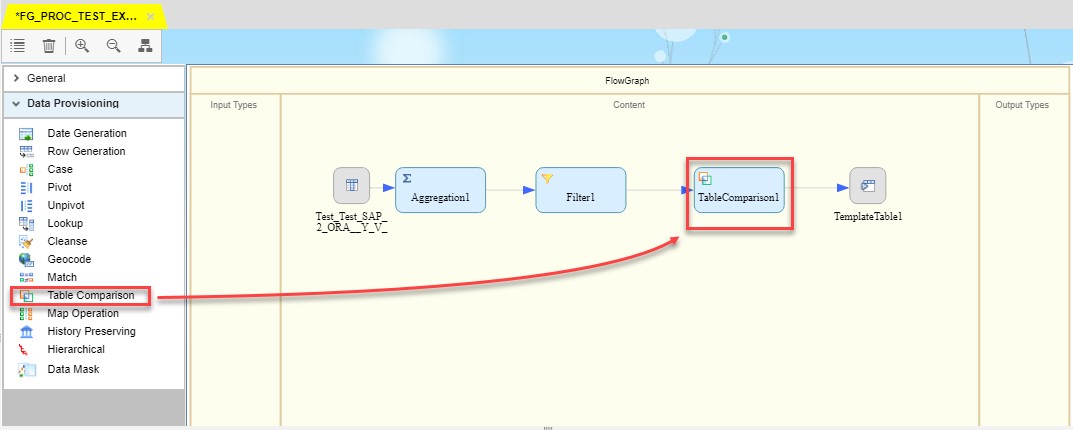
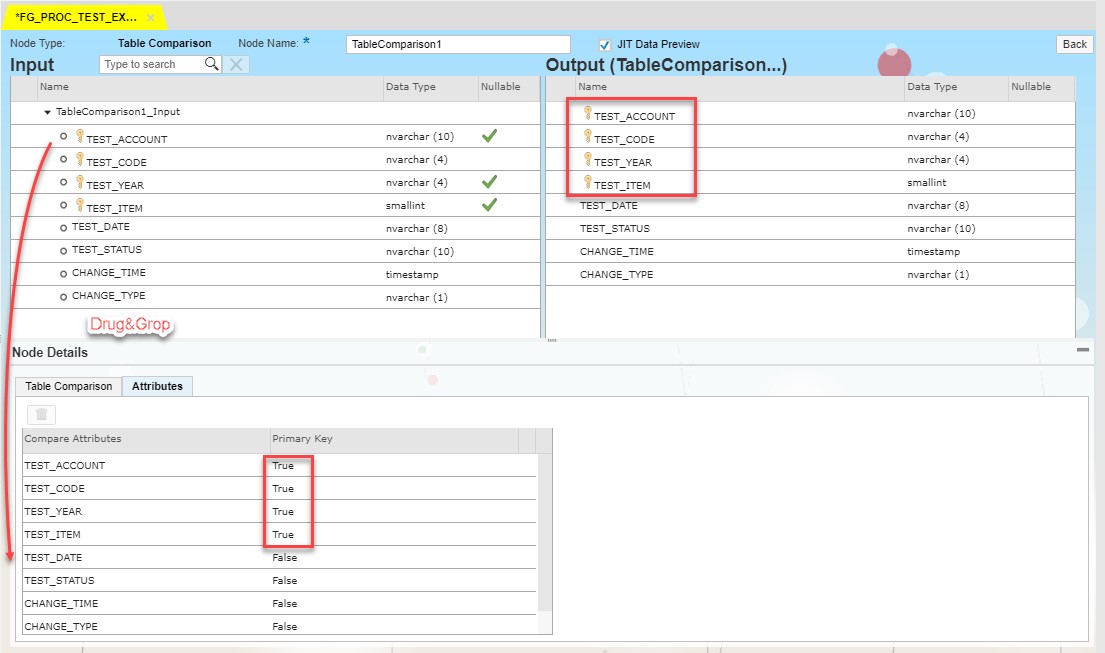
The following block is Table Comparison. It compares two tables and produces the difference between them as a dataset with rows flagged as INSERT, UPDATE, or DELETE. In my case it will compare data in target ORACLE table with source S/4 hdbview. This block will be put between Filters and Target Table.
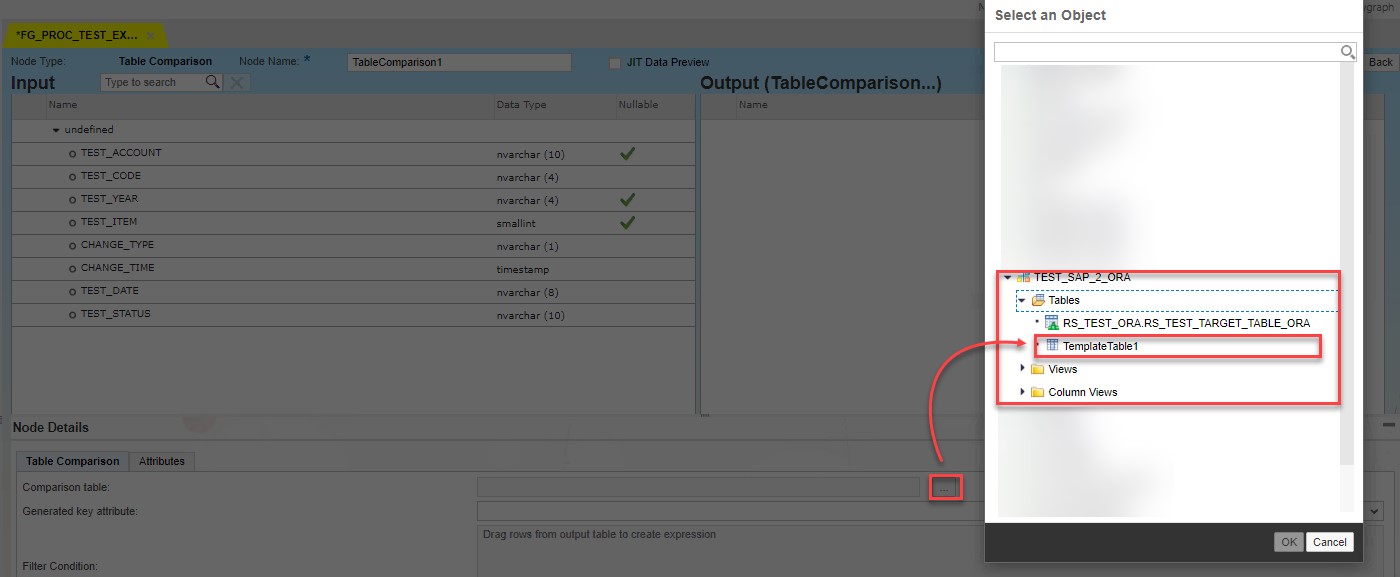
Using Search Help corresponding table is selected.
On the Attribute tab all the compared fields should be collected and Primary Keys should be assigned accordingly.
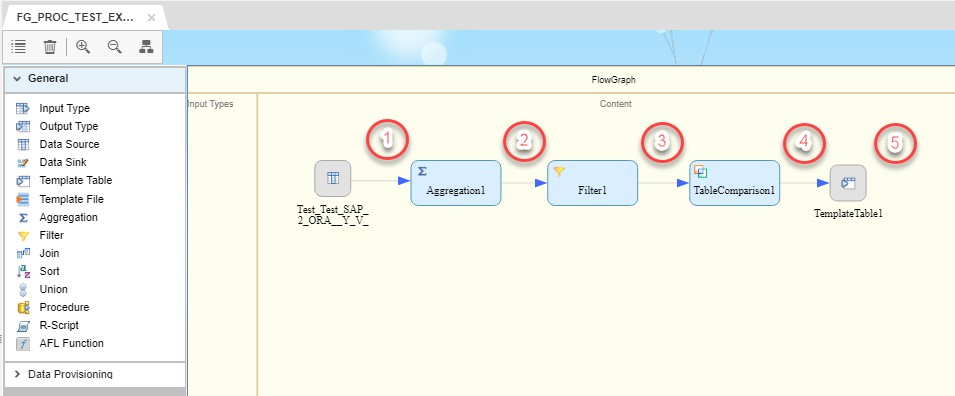
After all the steps Flowgraph should be saved. If everything is correct a corresponding message will appear in the Console. Then we Run the Flowgraph pressing ![]() button. In the console we see the following message:
button. In the console we see the following message:
![]()
Using JIT preview I will check the data flow after each of the blocks.
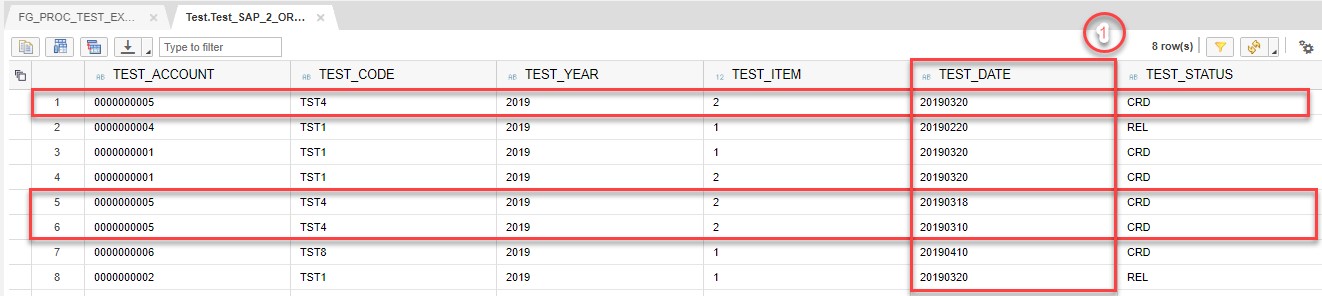
On the first step we have the following set of data:
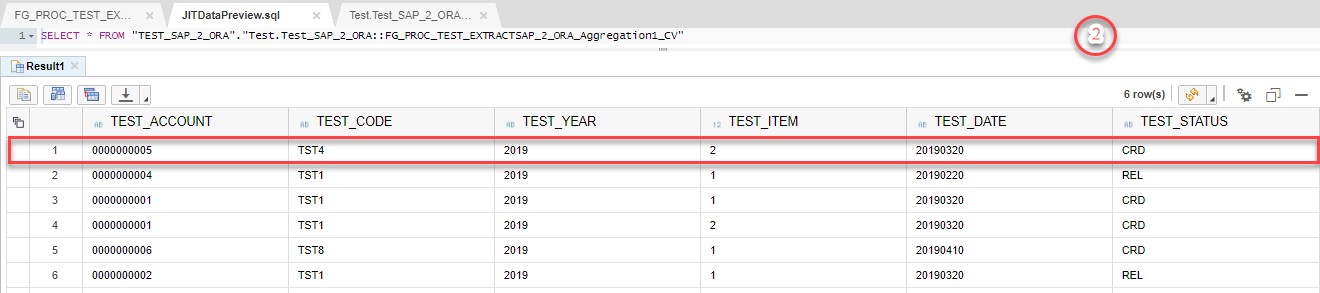
On the second step Aggregation block will leave entries only with MAX TEST_DATE.
On the third step Filter block will add 2 fields to the structure and populate with corresponding data.
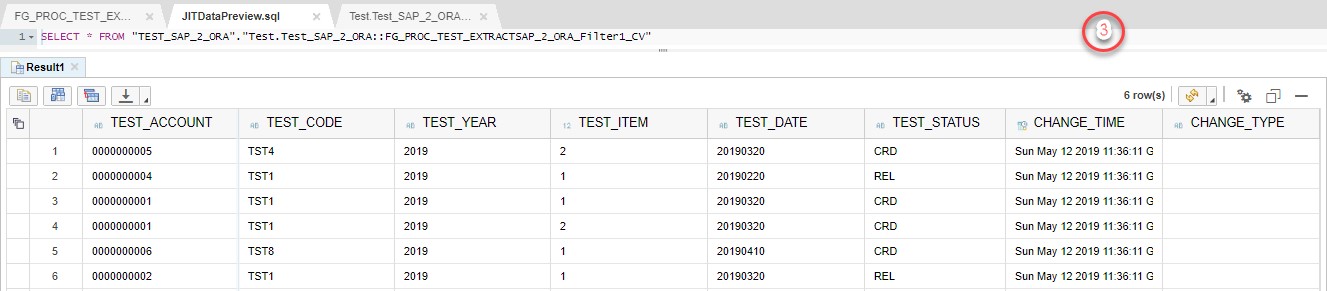
Table Comparison block will compare data stored in Template Table and newly entered data set. System automatically creates additional field _OP_CODE and all the fields which are in the table structure with prefix _BEFORE in order to proceed with comparison.

On the last step we can see the new data set in the Template Table:

In case you’d have any questions about SDI please feel free to comment under the blog.
The post Smart Data Integration (SDI) flowgraph data processing appeared first on INT4.
]]>